把一本长篇书拆成可保存的本地记忆,让 AI 书童在后续问答里拥有更长的阅读背景。
| 用户问题 | 长篇小说经常超出 AI 上下文窗口,普通伴读容易只记得当前页。 |
|---|---|
| 功能做法 | 分块梳理全书,保存章节摘要、人物、地点、事件和线索,后续提问时按需调用。 |
| 核心价值 | 让 AI 书童拥有更长的书内背景,适合几十万字以上的小说和系列文本。 |
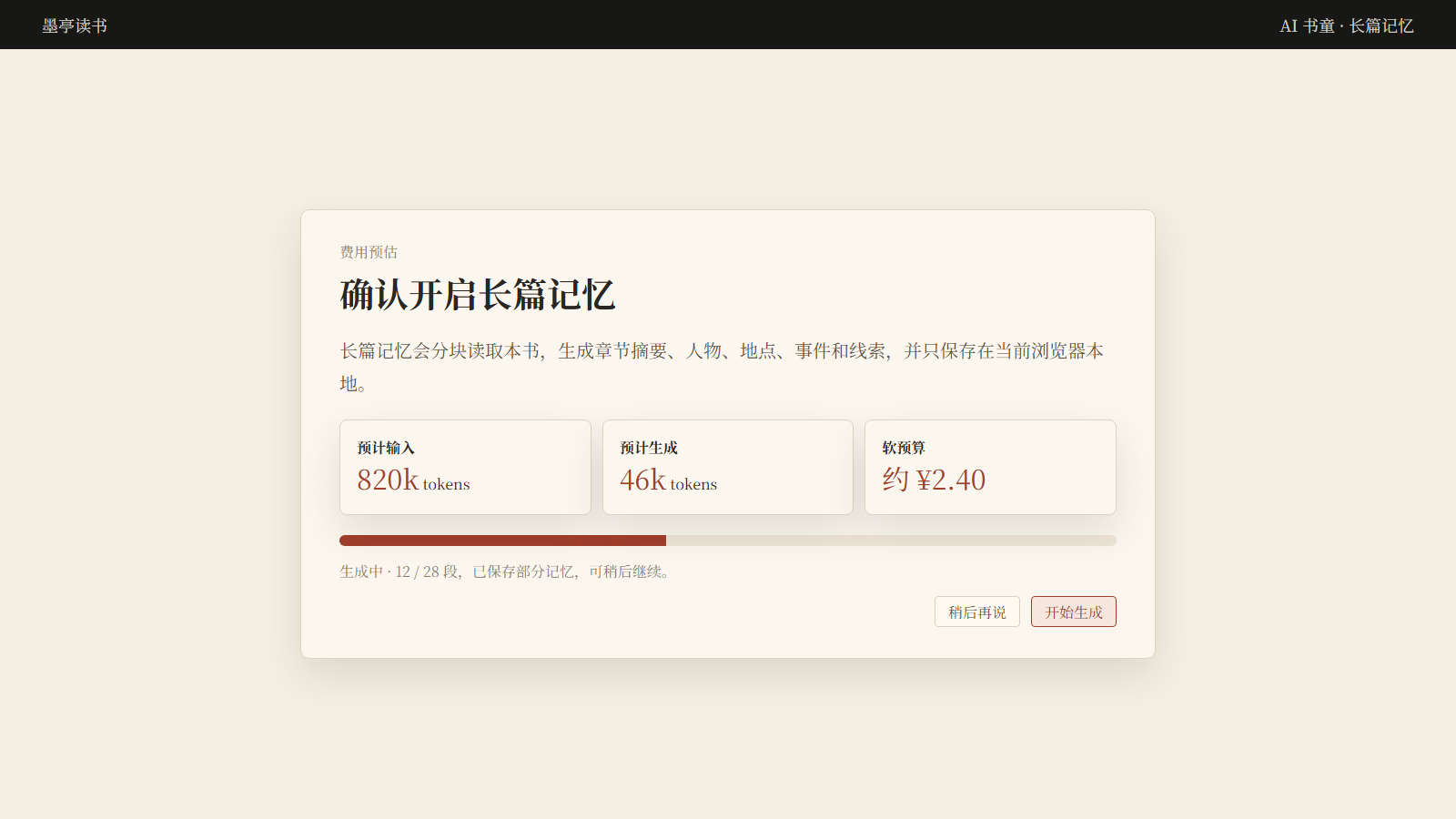
| 使用边界 | 会多次调用 AI,因此启动前显示 tokens 和费用预估,并由用户确认。 |
这个需求从哪里来
AI 有上下文窗口限制。一本几十万字甚至上百万字的小说,不可能每次提问都把全文塞给模型。结果就是:AI 能回答当前页,却记不住前面几百章的人物、伏笔和事件。
长篇记忆解决的是“伴读不能陪完整本书”的问题。它不试图一次性把全书塞进模型,而是把长篇拆成小段,逐段生成可复用的摘要和线索。
功能怎么工作
启动长篇记忆前,墨亭会估算本次需要发送的 tokens 和可能费用,用户确认后才开始。生成过程中,书籍会被分块处理,每块提取摘要、人物、地点、事件和未完成线索,结果只保存在当前浏览器本地。
如果中途暂停,墨亭会保留已完成部分,下次可以继续。后续向 AI 书童提问时,墨亭会根据问题挑选相关记忆片段,加上当前章节内容一起发给 AI。
它带来的价值
第一,突破单次上下文限制,让 AI 不再只看见眼前这一页。第二,适合长期追更或慢慢读的小说,隔一段时间回来也能快速接上。第三,减少重复解释:你不用每次都提醒 AI 某个人是谁、某条线索前面发生过什么。
长篇记忆不是云端同步,也不是训练模型。它只是把这本书的伴读档案整理好,存在你自己的浏览器里。
费用为什么要确认
长篇记忆会多次调用 AI,成本比单次问答高。墨亭必须在启动前把预估费用讲清楚,让用户知道自己要做什么、可能花多少。这也是我们坚持自带 Key 模式的原因:费用直接发生在你的模型账户里,墨亭不参与计费。
常见问题
长篇记忆不会把书上传到墨亭服务器。内容发送给你当前配置的 AI 服务,结果保存在浏览器本地。它适合超出上下文限制的长篇,短书通常用预热全书就够了。
试试墨亭:打开 tingread.cn,导入一本书,从你正在读的那一页开始。